Alexandre Ramé
Home
Publications
Talks/Posts
Teaching
Books
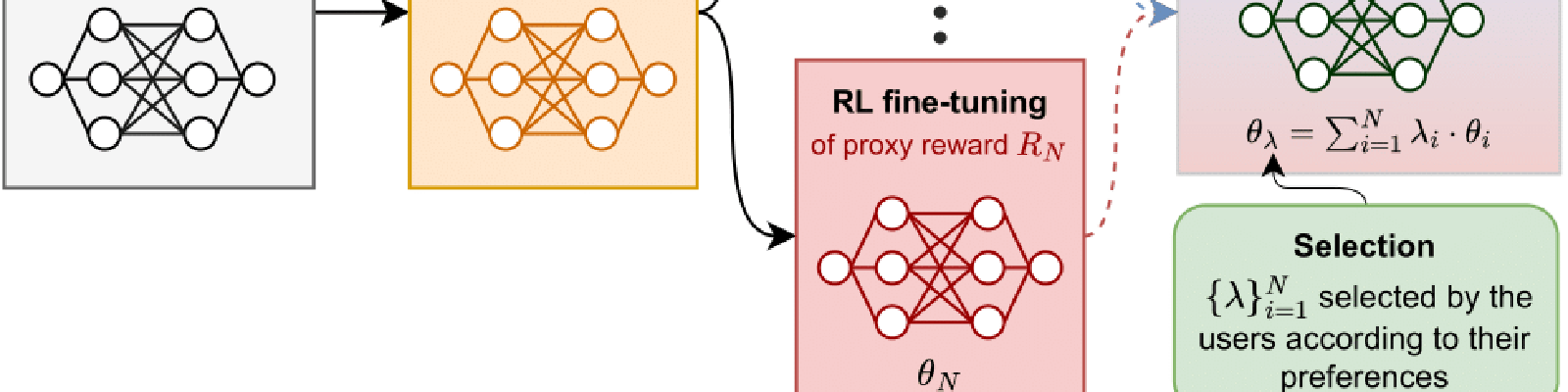
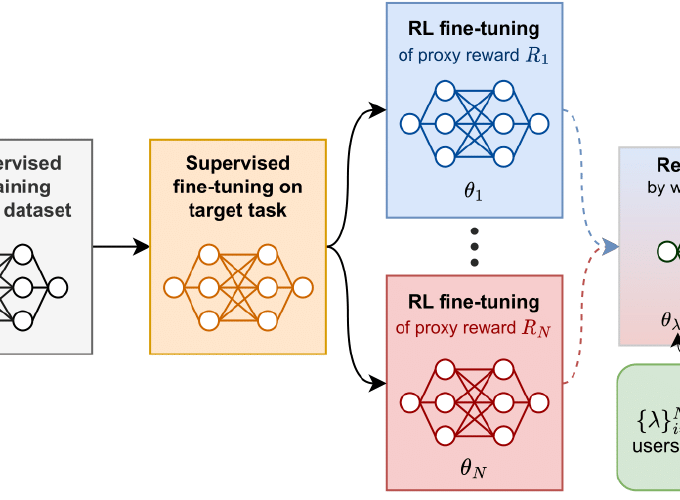
Rewarded soups: towards Pareto-optimal alignment by interpolating weights fine-tuned on diverse rewards
**Alexandre Ramé**
,
Guillaume Couairon
,
Mustafa Shukor
,
Corentin Dancette
,
Jean-Baptiste Gaya
,
Laure Soulier
,
Matthieu Cord
21 May, 2023
Rewarded soups: towards Pareto-optimal alignment by interpolating weights fine-tuned on diverse rewards
**Alexandre Ramé**
,
Guillaume Couairon
,
Mustafa Shukor
,
Corentin Dancette
,
Jean-Baptiste Gaya
,
Laure Soulier
,
Matthieu Cord
21 May, 2023
Date
May, 2023
Links
PDF
Cite
Code
Project
Poster
Slides
Next
Beyond task performance: evaluating and reducing the flaws of large multimodal models with in-context-learning
Previous
UnIVAL: Unified Model for Image, Video, Audio and Language Tasks
Cite
×