Selected Publications
Gemma 3 Technical Report
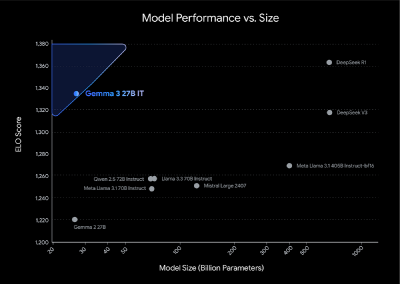
We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. In particular, our novel post-training recipe significantly improves the math, chat, …
On Teacher Hacking in Language Model Distillation
We study teacher hacking: does over-optimization of the distillation objective harm the ground-truth performance?
Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch
We improve DiLoCo in three ways. First, we synchronize only subsets of parameters in sequence. Second, we allow workers to continue training while synchronizing. Third, we quantize the data exchanged by workers.
Diversity-Rewarded CFG Distillation
we introduce diversity-rewarded CFG distillation, a novel finetuning procedure that distills the strengths of CFG while addressing its limitations using RL and weight averaging.
Gemma 2: Improving Open Language Models at a Practical Size
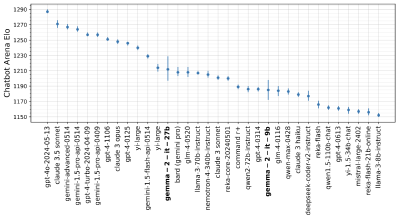
We introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameter.
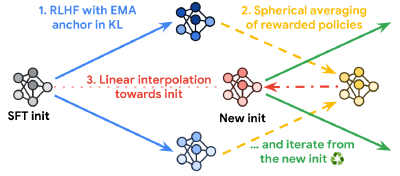
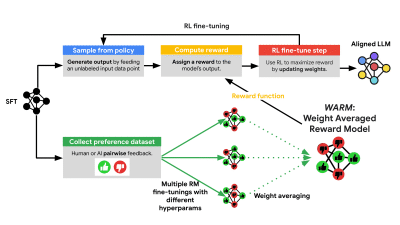
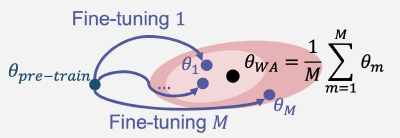
Beyond task performance: evaluating and reducing the flaws of large multimodal models with in-context-learning
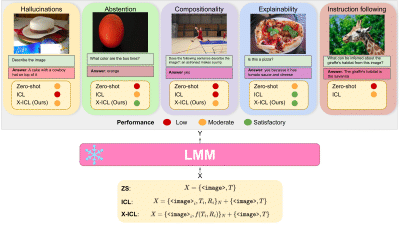
We investigate large multimodal models and their limitations such as hallucinations and lack of explainability. We then show that multimodal in-context learning can reduce some of these flaws.
Rewarded soups: towards Pareto-optimal alignment by interpolating weights fine-tuned on diverse rewards
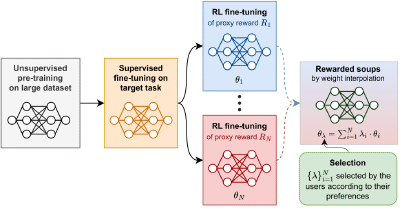
We introduce rewarded soup, a new strategy to trade-off between multiple rewards when fine-tuning foundation models with RLHF; we first learn one network for each reward, and then linearly interpolate their weights.