Filter by type:
Gemma 3 Technical Report
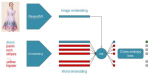
We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion …
On Teacher Hacking in Language Model Distillation
We study teacher hacking: does over-optimization of the distillation objective harm the ground-truth performance?
Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch
We improve DiLoCo in three ways. First, we synchronize only subsets of parameters in sequence. Second, we allow workers to continue …
Diversity-Rewarded CFG Distillation
we introduce diversity-rewarded CFG distillation, a novel finetuning procedure that distills the strengths of CFG while addressing its …
Gemma 2: Improving Open Language Models at a Practical Size
We introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion …

WARP: On the Benefits of Weight Averaged Rewarded Policies
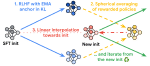
To improve the trade-off between KL and reward during RLHF, we leverage the ability to merge LLMs by weight averaging.
WARM: On the Benefits of Weight Averaged Reward Models
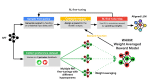
We introduce a new strategy for reward modeling in alignment via RLHF: we merge multiple reward models into one that’s more …
Diverse and Efficient Ensembling of Deep Networks
During my PhD, I analyzed how ensembling via weight averaging can improve out-of-distribution generalization and alignment. This …
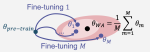
Beyond task performance: evaluating and reducing the flaws of large multimodal models with in-context-learning
We investigate large multimodal models and their limitations such as hallucinations and lack of explainability. We then show that …

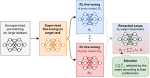
UnIVAL: Unified Model for Image, Video, Audio and Language Tasks
UnIVAL is a 0.25B-parameter unified model that is multitask pretrained on image and video-text data and target image, video and …
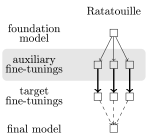
Model Ratatouille: Recycling Diverse Models for Out-of-Distribution Generalization
We propose a new fine-tuning strategy that improves OOD generalization in computer vision by recycling and averaging weights …
Diverse Weight Averaging for Out-of-Distribution Generalization
To improve out-of-distribution generalization on DomainBed, we average diverse weights obtained from different training runs; this …
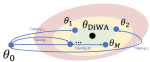
Fishr: Invariant Gradient Variances for Out-of-Distribution Generalization
We introduce and motivate a new regularization that enforces invariance in the domain-level gradient variances across the different …
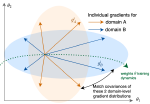
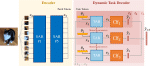
DyTox: Transformers for Continual Learning with DYnamic TOken eXpansion
We propose a new dynamic transformer architecture for continual learning with state-of-the-art performances.
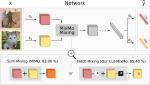
MixMo: Mixing Multiple Inputs for Multiple Outputs via Deep Subnetworks
We introduce a new generalized framework for learning multi-input multi-output subnetworks and study how to best mix the inputs. We …
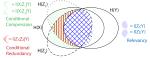
DICE: Diversity in Deep Ensembles via Conditional Redundancy Adversarial Estimation
Driven by arguments from information theory, we introduce a new learning strategy for deep ensembles that increases diversity among …
CORE: Color Regression for Multiple Colors Fashion Garments
We detect continuous colors for fashion garments using a new architecture.
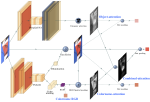
OMNIA Faster R-CNN: Detection in the Wild through Dataset Merging and Soft Distillation
We improve performances of object detectors via combining different datasets through soft distillation.

Leveraging Weakly Annotated Data for Fashion Image Retrieval and Label Prediction
We present a method to learn a visual representation adapted for e-commerce products.